[MySQL] 가용성과 확장성을 위한 Database Replication
DB Replication이 왜 필요할까?

다음과 같이 데이터베이스를 한 대만 운영하는 아키텍처가 있다고 가정해보자. 모든 데이터에 대한 읽기와 쓰기 작업은 하나의 MySQL 데이터베이스에서 수행된다. 만약, 갑자기 서비스 홍보가 너무 잘 되어서 트래픽이 폭주했다고 가정해보자.
(본 포스팅에서는 주제와 벗어나는 서버 부하는 신경쓰지 않는다.)
DB 관점에서 보면 다음과 같이 크게 2가지 문제가 발생할 수 있다.
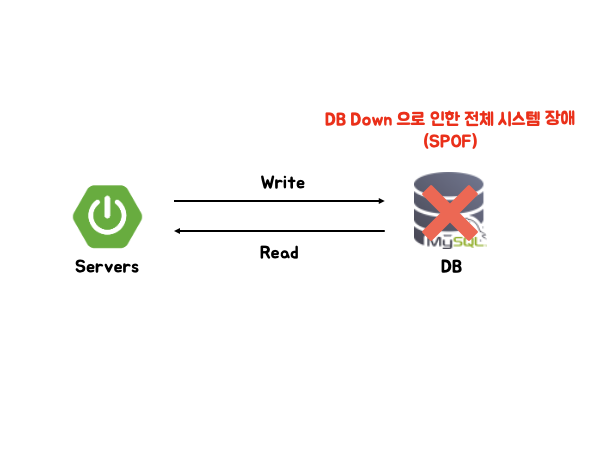
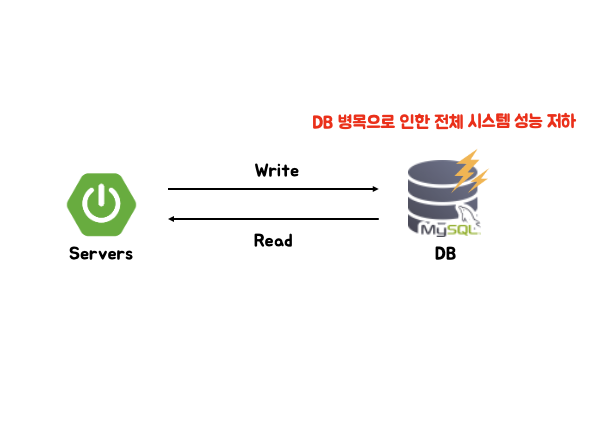
[1. SPOF]
데이터베이스를 한 대만 운영하는 환경에서는 데이터베이스가 다운될 경우 전체 시스템 장애로 이어질 수 밖에 없다. 백업으로 사용할 데이터베이스도 없고 HA 구성도 되어있지 않으니 당연하다. 이처럼 하나의 요소에 생긴 장애가 시스템 전체 장애로 이어지는 것을 SPOF (Single Point Of Failure) 라고 한다. 24시간 365일 정상적으로 동작해야하는 서비스에서 전체 시스템 장애는 비즈니스에 치명적인 영향을 끼칠 것이다.
[2. 성능 저하]
아키텍처가 서로 의존성을 가지고 복잡해질수록 애플리케이션의 성능은 각 리소스 성능에 의존적이게 된다. 서버가 아무리 빠르게 로직을 처리할 수 있더라도 데이터베이스의 처리 속도가 느리다면 전체 시스템 성능은 느려질 수밖에 없다. 위처럼 같이 하나의 데이터베이스를 사용하는 환경에서는 모든 데이터에 대한 읽기/쓰기 작업이 하나의 데이터베이스를 통해 이루어지기 때문에 부하가 늘어나고 자연스레 성능도 떨어지게 된다. 하나의 MasterDB를 Scale Up하여 성능을 높일 수도 있겠지만 앞서 언급한 SPOF를 피할 순 없을 것이다.
DB Replication (복제 구성)
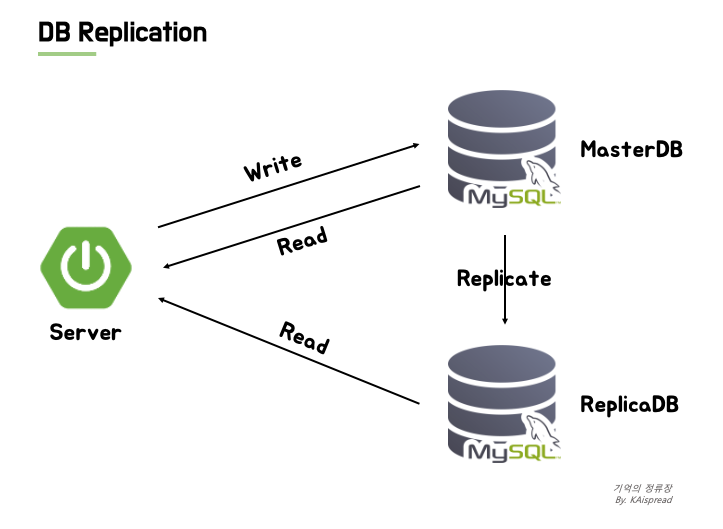
데이터베이스 Replication을 적용하면 앞서 언급한 문제를 해결할 수 있다. 원본 데이터를 소유하고 있는 서버를 Master, Master의 데이터를 복제하는 서버를 Replica 라고 한다. 이전에는 Master & Slave 구성이라고 불렀었는데, 최근엔 윤리적인 이유로 Master & Replica 혹은 Source & Replica 라고 부른다. 본 포스팅에서는 Source 와 Master를 동일한 의미로 사용하겠다.
애플리케이션 서버는 Master 서버에 데이터 쓰기 작업을 요청하고 Master 서버는 Replica 서버에 변경된 이벤트를 전송하여 데이터를 동기화한다. 읽기 작업은 Replica 서버로 요청하여 읽기 작업과 쓰기 작업의 부하를 분산시키는 셈이다. 예시 자료에서는 한 대의 Replica 서버를 두었지만, 1대의 Master 서버에 여러 Replica 서버를 두어서 대용량 트래픽에 적합한 Multi Replica 구성도 가능하다.
🚀 장점
[부하 분산 & 성능 최적화]
애플리케이션 서버는 Master 서버에 데이터 쓰기 작업을 요청하고 Master 서버는 Replica 서버에 변경된 이벤트를 전송하여 데이터를 동기화한다. 읽기 작업은 Replica 서버로 요청하여 읽기 작업과 쓰기 작업의 부하를 분산시키는 셈이다. 이를 통해 트래픽을 분산시켜 쿼리 성능을 향상시킬 수 있다. 예시 자료에서는 한 대의 Replica 서버를 두었지만, 1대의 Master 서버에 여러 Replica 서버를 두어서 대용량 트래픽에 적합한 Multi Replica 구성도 가능하다.
[데이터 백업과 failover]
평소엔 Master 서버에 쓰기 작업을, Replica 서버에 읽기 작업을 요청하다가 Master 서버에 장애가 발생할 경우 백업용 Replica 서버를 Master 서버로 승격시켜 SPOF를 피할 수 있다. 이처럼 어떤 리소스에 장애가 발생했을 때 예비 시스템을 통해 자동으로 장애를 복구할 수 있는 기능을 failover 라고 한다. 오픈소스인 MMM과 MHA를 통해 데이터베이스에 대해 HA 구성을 할 수 있다.
[데이터 분석]
분석용 쿼리는 대용량의 데이터를 조회하는 경우가 많다. 쿼리 자체도 무거운 편이기때문에 대부분 데이터베이스에 부하를 많이 주게된다. Master 서버에서 이러한 작업을 처리하게 되면 데이터베이스 성능이 떨어져, 실제 서비스에 문제가 생길수도 있다. 데이터 분석용 Replica 서버에서 분석용 쿼리를 실행하면 거의 동일한 데이터 셋으로 실 서비스에 문제 없이 데이터를 분석할 수 있다.
[데이터 지리적 분산]
지금도 많은 서비스들은 전 세계적으로 서비스하고 있다. 데이터베이스 서버의 위치가 클라이언트로부터 지리적으로 멀리 떨어져있다면 Latency가 커지는 것이 당연할 것이다. Replication 을 통해 각 나라 혹은 지리적 요소에 데이터베이스를 위치 시킨다면 지리적 거리로 인한 Latency를 최소화할 수 있을 것이다.
단점
결과적으로 Replication 을 통해 데이터베이스 리소스를 이중화 할 수 있고 이는 백업, 확장, 분석, 분산 등 여러 장점을 가질 수 있다. 하지만 기본적으로 Replication은 비동기 통신을 통해 동기화되므로 데이터 정합성 문제가 발생할 수 있다. 이 때 정합성이 중요한 데이터는 Master 서버를 통해 조회하거나 차선책으로 반동기 복제 방식을 선택할 수 있는데 이 부분에 대해서는 후술하겠다.
Replication 동작 방식 [MySQL]
MySQL 기준의 Replication 동작 방식은 다음과 같다.
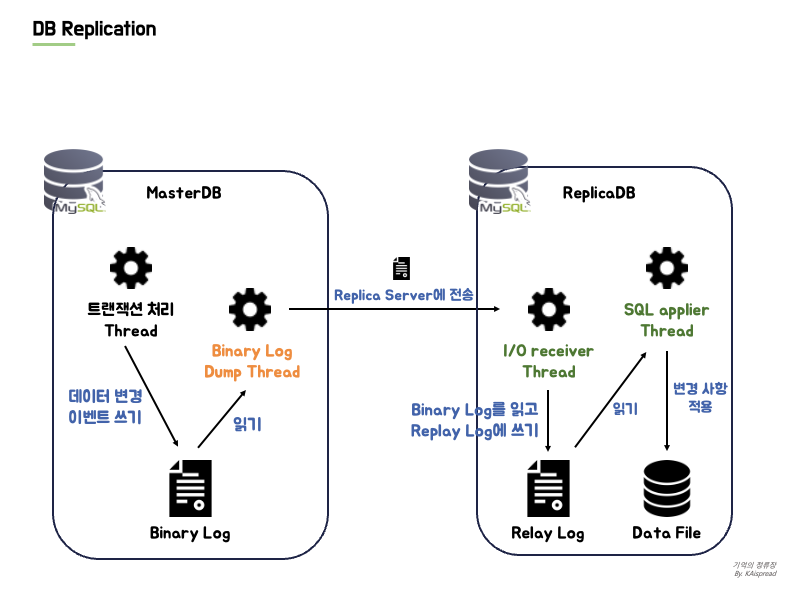
MySQL은 Replication 환경에서 3개의 쓰레드를 생성한다.
- [Master] Binary Log Dump Thread
- [Replica] I/O receiver Thread
- [Replica] SQL applier Thread
[Binary Log Dump Thread]
Replica 서버로부터 Replication 요청이 발생했을때 Master 서버에 생성되는 쓰레드이다. 트랜잭션 처리 쓰레드가 쓴 Binary Log를 읽어, 변경 이벤트를 Replica Server에 전송하는 역할을 한다. 정확히는 Replica 서버에 I/O receiver Thread 로 전송한다. Binary Log를 읽을 때 일시적으로 Lock을 걸고 읽기 작업이 끝나면 즉시 해제한다.
[I/O receiver Thread]
Replication 시작 명령어인 START REPLICA 명령이 실행되면 Replica 서버에 생성되는 쓰레드이다. Master 서버의 Binary Log Dump Thread 와 연결되며, Binary Log를 읽고 자신의 Relay Log에 복사하는 역할을 수행한다.
[SQL applier Thread]
Replica 서버에 생성되는 쓰레드로, Relay Log에서 이벤트를 읽어, 그 안에 포함된 변경 내용을 Replica 서버의 스토리지 엔진에 적용하여 데이터 파일을 변경한다.
복제의 타입
Replica 서버는 Master 서버의 Log로부터 변경된 이벤트를 가져온다.
이 때 Binary Log에 기록된 변경 내역들을 식별할 수 있는 2가지 방법이 있다.
- Binary Log 파일 위치 기반 복제 -> ex) Binary-log.0000002:130
- 글로벌 트랜잭션 ID 기반 복제 (GTID) -> ex) af930184-13734-sf184-3dfa:18
Binary Log 파일 위치 기반 복제는 Master 서버에서만 식별 가능한 값을 통해 변경 이벤트를 확인하게 된다. 이와 같은 방식은 Master 서버 장애로 Replica 서버가 Master 로 승격될 때 데이터 복제 과정에 더 많은 시간이 소요된다는 단점이 있다.
반면 GTID (Global Transaction ID)는 다른 모든 서버에서 식별할 수 있는 고유의 값을 통해 이벤트를 식별하게 된다. 이와 같은 방식은 크게 2가지 이점이 있다.
1. Failover 및 Replica 서버 스위칭이 쉬워진다.
이전 Master 서버에서 적용된 마지막 이벤트 그룹의 GTID를 통해 새 Master 에서 복제를 어디에서 다시 시작해야하는지 쉽게 알 수 있다. 특정 바이너리 로그 파일과 오프셋을 추적해야하는 기존 방법보다 훨씬 효율적인 방법이다.
2. crash-safe 한 방식으로 Replica 의 상태가 기록된다.
GTID를 활성화 할 경우, Replica 서버는 I/O receiver Thread 와 SQL applier Thread를 통해 데이터 동기화를 진행하면서 mysql.gtid_slave_pos 시스템 테이블에 GTID와 트랜잭션 실행 정보를 Local에 저장하게 된다. Replica 서버에 장애가 발생하여 복제가 중단되었다 하더라도 GTID를 통해 기록된 정보가 실제 변경사항과 일치하는지 확인할 수 있게된다. 즉, crash-safe 하게 복제본의 상태가 기록되는 것이다.
MySQL은 5.6 버전부터, MariaDB는 10.0 이후부터 GTID를 지원하고 있다. 공식문서에서도 GTID 활성화를 권고하고 있으니 이후 실습포스팅에는 GTID를 적용하도록 하겠다.
더 많은 내용은 아래 공식 문서에서 확인 가능하다.
https://mariadb.com/kb/en/gtid/#using-current_pos-vs-slave_pos
Global Transaction ID
Improved replication using global transaction IDs.
mariadb.com
Replication 방식
MySQL 이 지원하는 Replication 방식은 Async(비동기) 방식과 Semi-sync(반동기) 방식으로 두가지이다. (기본 동작 방식은 Async)
- 비동기 복제 : Master 서버가 Replica 서버에 변경 이벤트가 정상적으로 전달되었는지 확인하지 않는다.
- 반동기 복제 : Master 서버는 Replica 서버가 변경 이벤트를 Relay Log 에 기록 후 Ack 응답을 보내면 그 때 트랜잭션을 커밋한다.
비동기 복제
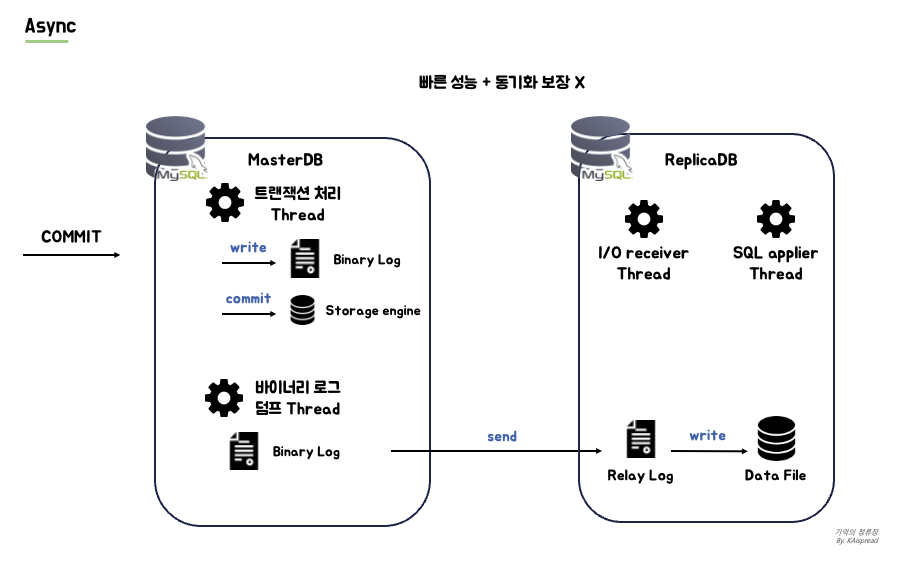
비동기 복제는 복제 이벤트가 Replica 서버에 전달되었는지에 대한 여부와 상관없이 COMMIT을 완료하는 복제 방식이다. 동작 방식은 다음의 순서로 이루어진다.
- COMMIT 발생
- Replica 서버의 I/O receiver thread 가 Master 서버의 Binary Log Dump Thread 에 Binary Log 파일 요청
- Binary Log Dump Thread 에서 비동기로 Replica 서버의 I/O receiver Thread에 Binary Log 전송
- I/O Thread 가 Relay Log를 기록하고 SQL applier Thread 는 변경 내용을 적용함
비동기 복제 방식에서 중요한 점은, Master 서버에서 Replica 서버의 이벤트 적용 성공/실패 여부를 신경쓰지 않는다는 점이다. 그저, Binary Log Dump Thread 가 Replica 서버에 변경된 이벤트 로그를 보내주기만 한다. Replica 서버 입장에서도 COMMIT 직후, Master 서버에 장애가 발생하더라도 이를 알지 못하게된다.
Replication 여부와 관계 없이 작업을 처리하기 때문에 빠른 성능을 보장하지만 변경된 이벤트가 Replica 서버의 Relay Log에 기록되지 않을 수 있기 때문에 상대적으로 데이터 정합성 측면에서 불리한 방식이다.
반동기 복제

반동기 복제는 복제 이벤트가 Replica 서버의 Relay Log에 쓰여진 이후 COMMIT 되는 방식이다. Relay Log에 쓰여진 이후 COMMIT 되는 것이지, Data File에 데이터가 변경되었다는 것은 아니다.
- COMMIT 발생
- Binary Log Dump Thread가 Replica 서버의 I/O receiver Thread 에 Binary Log를 보냄
- I/O receiver Thread 가 Binary Log를 읽고 Relay Log에 변경 이벤트를 기록함.
- Relay Log를 성공적으로 작성했다는 ACK 응답을 보냄
- Master 서버는 ACK을 수신한 뒤 Engine Commit 수행
반동기 복제 방식에서는 비동기 복제 방식과 다르게 Binary Log가 Replica 서버에 전송되고 Relay Log에 쓰여진 이후 Engine Commit을 수행한다. Replica 서버 Relay Log에 변경 이벤트 동기화를 보장하지만 실제 Storage Engine으로부터 Data File이 동기화된 것은 아니다. 따라서, 데이터 정합성 문제가 발생할 가능성은 있지만 그 확률이 비동기 복제 방식보다는 낮다.
Semi-sync 방식에서는 2가지 모드를 지원하는데, AFTER_COMMIT 모드는 Engine Commit 이 발생한 이후 Binary Log 를 Replica 서버에 보낸다. 앞서 설명한 방식은 AFTER_SYNC 방식이다.
마무리
본 포스팅에서는 MySQL와 MariaDB 자료를 기준으로 Replication 에 대한 내용들을 알아보았다. 이후 포스팅에서는 2대의 데이터베이스 서버에서 실제로 Replication 을 구성해보고 이를 Spring Boot 애플리케이션과 연동하여 @Transaction readOnly 설정 값에 따라 트래픽을 분리시켜보겠다.
이후에는 Semi-sync 적용과 MMM 또는 MHA를 통한 HA 구성까지 포스팅 할 예정이다.
Reference
https://mariadb.com/kb/en/setting-up-replication/
Setting Up Replication
Learn about MySQL Server Replication and examples of enabling replication for MySQL with MariaDB.
mariadb.com