[Java] 멀티 스레드 환경에서 발생할 수 있는 동시성 이슈와 해결 방법
개요
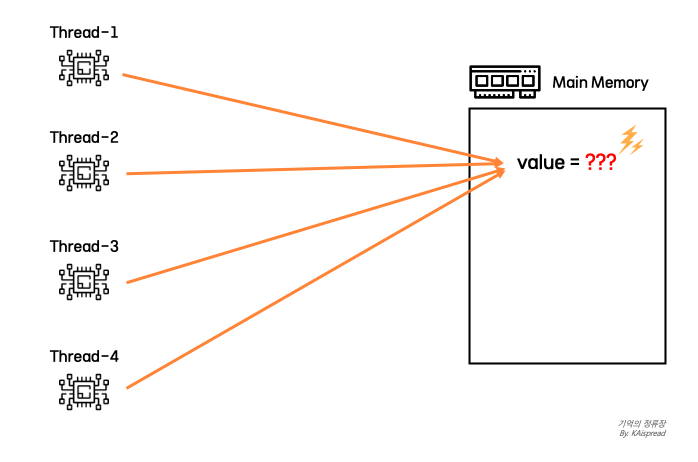
멀티 스레드를 사용하는 환경에서 각 스레드가 공유 자원에 동시에 접근하는 상황이라면 경쟁상태(Race condition)가 발생할 수 있습니다. 경쟁상태가 발생하게 되는 원인은 가시성(Visibility)과 원자성(Mutual Exclusion)을 보장하지 못했기 때문인데요, Java에서는 synchronized 키워드와 Atomic Type, Concurrent Collection 등을 통해 이와 같은 동시성 문제를 해결할 수 있습니다.
본 포스팅에서는 멀티 스레드 환경에서 발생할 수 있는 문제에 대해 설명하고 이를 해결할 수 있는 sychronized, volatile 키워드와 Atomic Type에 대한 내용을 다루겠습니다.
본 포스팅의 주제와 연관된 핵심적인 개념들은 다음과 같습니다.
공유자원 (shared data)
- 여러 스레드가 동시에 접근할 수 있는 자원
임계영역 (critical section)
- 공유자원들 중 여러 스레드가 동시에 접근했을 때 문제가 생길 수 있는 부분
경쟁상태 (race condition)
- 둘 이상의 스레드가 공유자원을 병행적으로 읽거나 쓰는 동작을 할 때 타이밍이나 접근 순서에 따라 실행 결과가 달라지는 상황
원자성
동시성 이슈 관점에서 원자성이란 공유 자원에 대한 작업 단위가 더이상 쪼갤 수 없는 하나의 연산인 것 처럼 동작하는 것을 말합니다. 간단한 예시를 통해 원자성에 대해 알아보겠습니다.
@Getter
public class ClickCountService {
private int clickCount;
public ClickCountService() {
this.clickCount = 0;
}
// 클릭 횟수 + 1
public void click() {
clickCount += 1;
}
}사용자의 클릭 횟수를 카운팅하기 위한 클래스가 있습니다. 이 클래스는 clickCount의 수를 1 더해주는 아주 간단한 click() 메서드를 포함하고 있습니다.
지금부터 이 클래스를 통해 여러 스레드가 공유 자원에 접근할 때 어떤 문제가 발생하는지 알아보겠습니다.
class ClickCountServiceTest {
@DisplayName("Click 횟수만큼 click-count 가 증가한다.")
@Test
void click() throws InterruptedException {
// given
final int clickCount = 10000;
ClickCountService service = new ClickCountService();
ExecutorService executor = Executors.newFixedThreadPool(50);
CountDownLatch counter = new CountDownLatch(clickCount);
// when
for (int i = 0; i < clickCount; i++) {
executor.execute(() -> {
service.click();
executorCount.countDown();
});
}
counter.await();
executor.shutdown();
// then
int result = service.getClickCount();
assertThat(result).isEqualTo(clickCount);
}
}다음은 동시성 환경을 조성하기위한 테스트 코드입니다. 동시성 환경을 조성하기 위해 java.util.concurrent 패키지의 ExecutorService와 CountDownLatch를 사용했는데요, 이들의 역할에 대해 간략히 소개하자면 다음과 같습니다.
- ExecutorService : 여러 태스크를 ThreadPool에 등록하고 실행하는 역할을 한다.
- CountDownLatch : 지정된 횟수의 요청이 전부 다 수행될때까지 기다리는 역할을 한다.
간단하게 50개의 스레드로 10,000번의 click() 메서드를 동시에 수행한다고 생각해주시면 됩니다. click() 메서드를 10,000번 호출하므로 당연히 clickCount 값도 10,000이여야 하는데요, 테스트 수행 결과를 확인해보겠습니다.
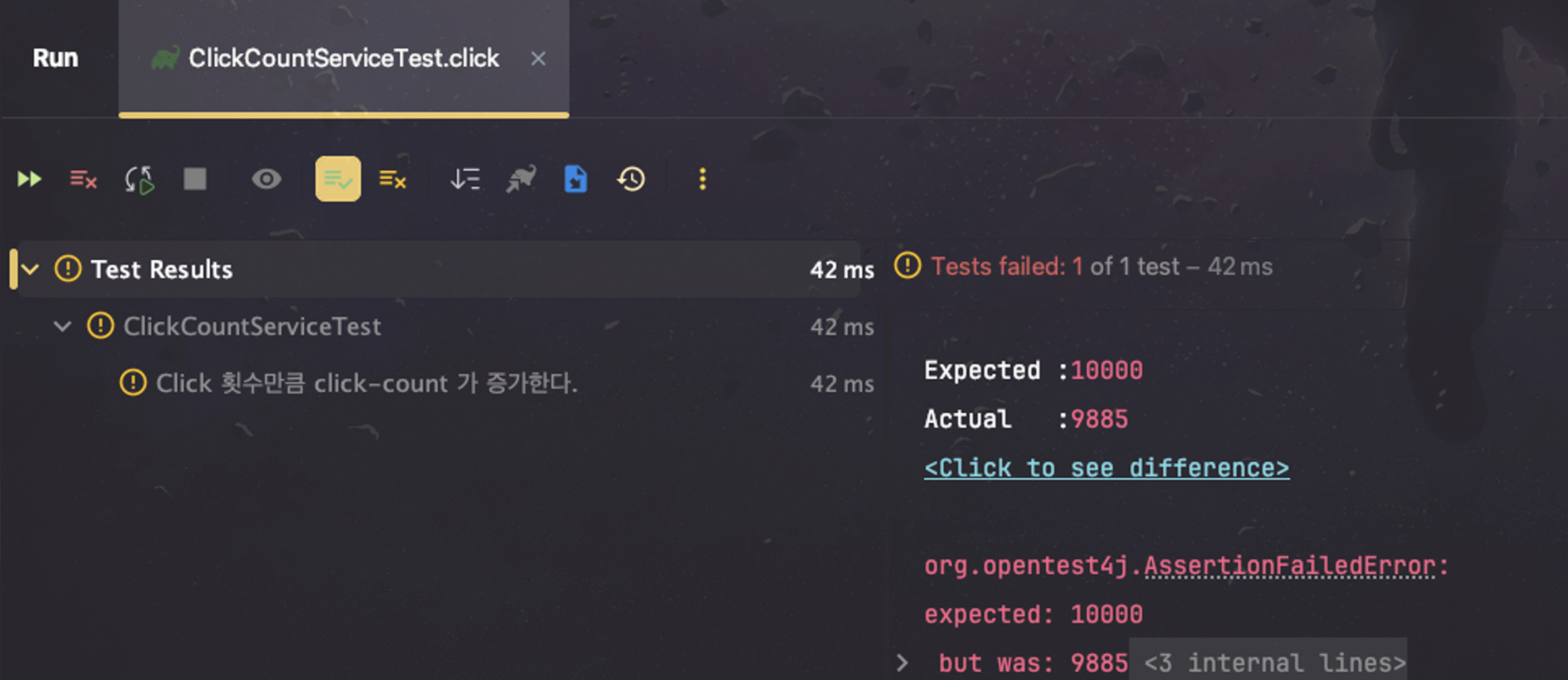
10,000이라는 값을 가지고 있을 것이라 예상했지만 실제 결과는 9,885라는 값을 가지고 있는 것을 확인할 수 있었습니다. 왜 기대와 다른 결과값을 가지고 있었을까요?
이는 clickCount의 숫자를 1 늘려주는 동작에서 원자성이 보장되지 않았기 때문입니다.
clickCount += 1;값에 1을 더해주는 이 간단한 코드는 사실 3가지 동작으로 이루어져 있습니다.
- clickCount 값을 가져온다.
- clickCount 값에 1을 더한다.
- 새로운 clickCount 값을 Main Memory에 반영한다.
그림을 통해 이 동작이 원자성이 보장되지 않은 이유에 대해 설명해드리겠습니다.

1번 Thread에서 clickCount += 1 코드를 수행하기 위해 메모리(또는 CPU Cache)에서 값을 가져오고 (50) 값에 1을 더합니다. (51) 이제 새로운 값을 반영해야하는데요, 이 때, Thread-1이 정해진 time slice를 모두 소모하여 context-switching이 발생합니다. OS는 현재 진행중이던 작업을 나중에 이어서 수행하기 위해 현재 스레드의 상태를 PCB에 저장하게 됩니다.
1번 Thread는 clickCount 값에 1을 더하는 연산까지 수행했지만, 아직 메인 메모리에 값을 반영하지 못했기때문에 2번 Thread는 이전 값인 50을 가져오게되고, 연산의 결과 값을 메모리에 저장합니다. 이후 다시 1번 Thread에서 진행중인 작업을 마무리하기위해 이전에 연산을 수행했던 값인 51을 다시 메모리에 저장하게됩니다.
결과적으로 2번의 작업이 일어났지만 메모리에는 +1된 값이 반영되어 원치 않은 결과가 발생하게 되는 것입니다. 이와 같이 작업이 여러개로 쪼개어져 원자성을 보장하지 못하는 상황을 원자성 문제라고 부릅니다.
이와 같은 문제를 해결하기 위해서는 동시에 하나의 스레드에서만 코드를 실행하거나 공유자원의 값을 변경하는 작업을 수행해야합니다. (Mutual-Exclusion 상호배제)
예시에서는 하나의 CPU 코어에서 여러 스레드가 공유자원에 접근하는 상황이지만, 멀티 코어 CPU 환경에서도 공유자원에 대해 동시에 읽기 작업이 일어나면 원자성 문제가 발생할 수 있습니다.
가시성
가시성이란 공유 자원에 반영된 값을 여러 스레드에서 볼 수 있어야한다는 것인데요. 마찬가지로 예시를 통해 가시성 문제가 발생한 상황에 대해서 알아보겠습니다.
@Slf4j
public class NoVisibility {
// 공유자원
public static boolean flag;
public static class FlagCall extends Thread {
@Override
public void run() {
log.info("Freeze");
while (!flag) { /* 대기중 */ }
log.info("Melt");
}
}
public static void main(String[] args) throws InterruptedException {
FlagCall flagCall = new FlagCall();
flagCall.start();
Thread.sleep(1000);
melt();
flagCall.join();
}
// 공유자원 수정
public static void melt() {
flag = true;
}
}공유자원인 flag 라는 boolean 값이 false 라면 대기상태에 빠지고 true라면 Melt 를 출력하는 코드입니다. 메서드 수행 후 1초 뒤 flag 값을 true로 변경해주었습니다.
flag 값을 true로 바꿔준다면 바로 반복문을 빠져나와 로그를 출력할 것이라 예상할 수 있는데요, 실제 결과는 어떨까요?
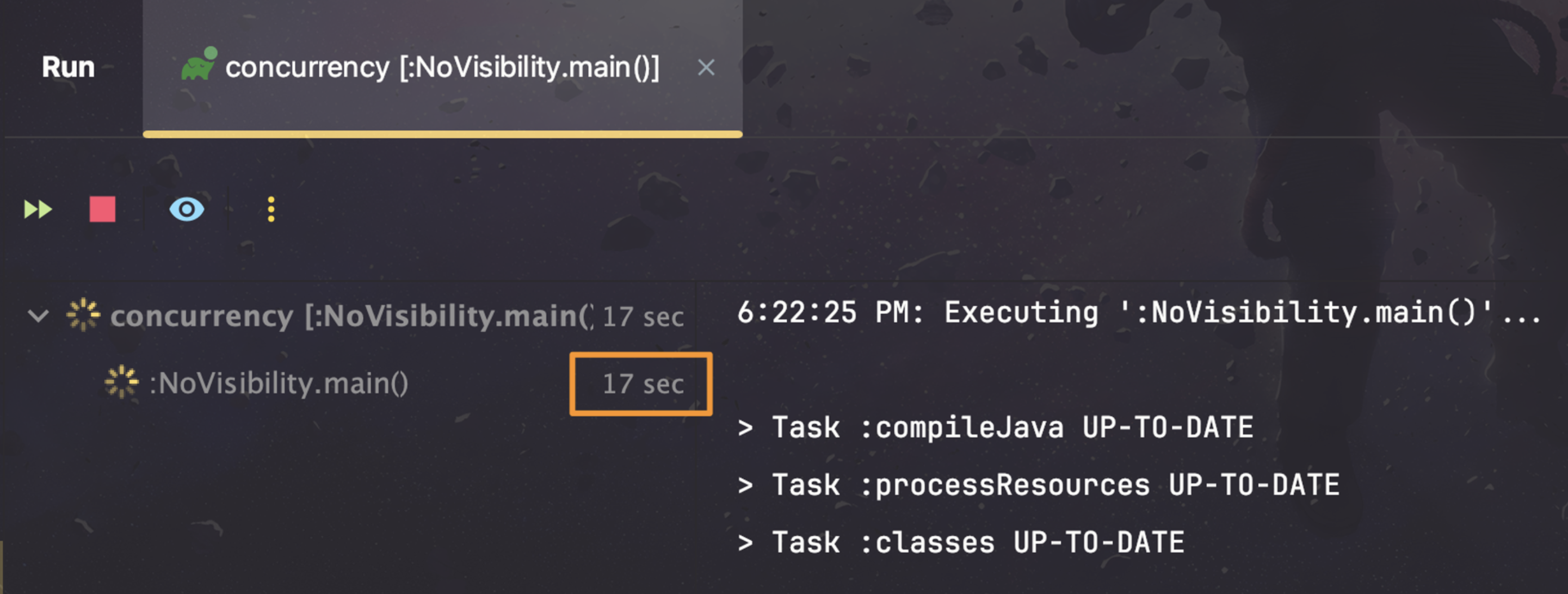
기대와는 다르게 1초가 지난 뒤에도 반복문이 계속 수행되고 있는 모습을 확인할 수 있었습니다. 분명 flag 값을 true로 변경해주었는데 왜 반복문을 빠져나오지 못하는 것일까요?
이번에도 그림을 통해 그 이유에 대해 설명해드리겠습니다.

일반적으로 CPU는 성능을 위해 자주 사용되는 값을 CPU Cache에 캐싱합니다. 쓰기 작업이 일어날때도 CPU Cache에 작업의 내용을 반영하고 이후 Main Memory에 반영하게 되는데요.
다른 스레드에서 flag 값을 수정하여 메인 메모리에 반영했다고 하더라도 CPU Cache에 이미 flag 값이 있기 때문에 이전 값(false)을 계속 참조하게되어 반복문이 끝나지 않던 것입니다. 이처럼 스레드에서 변경한 내용을 다른 스레드에서 보지 못하는 문제를 가시성 문제라고 합니다.
이를 해결하기 위해서는 값을 CPU Cache에 캐싱하는 것이 아니라, 항상 Main Memory로만 읽고/쓰도록하면 됩니다. Java에서는 volatile 키워드로 가시성 문제를 해결할 수 있습니다.
volatile
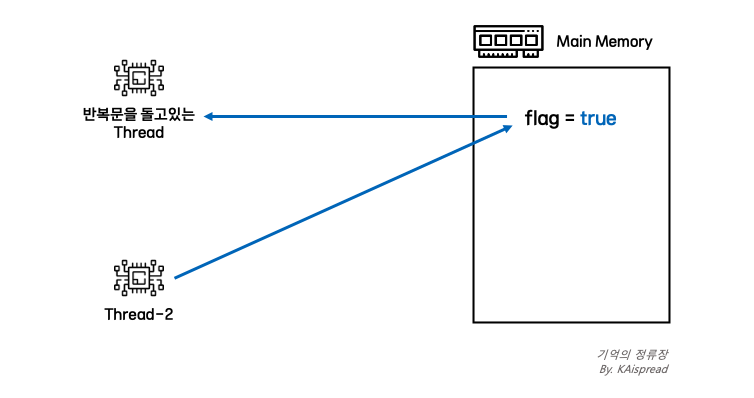
volatile은 Java 언어에서 가시성을 보장하기위해 지원하는 키워드입니다. volatile 키워드는 변수에만 붙일 수 있으며 해당 키워드가 붙은 변수는 CPU Cache에 쓰여지지 않고 Main Memory에서만 읽기/쓰기 작업이 이루어지게 됩니다. 따라서, volatile은 해당 변수가 동시성 이슈가 발생할 수 있는 변수임을 알려주는 키워드이기도 합니다.
@Slf4j
public class NoVisibility {
public static volatile boolean flag;
...
}가시성 문제 예제 코드에서 공유 변수에 volatile 키워드를 붙여주었습니다. 이전과는 다른 결과가 나오는지 확인해보겠습니다.
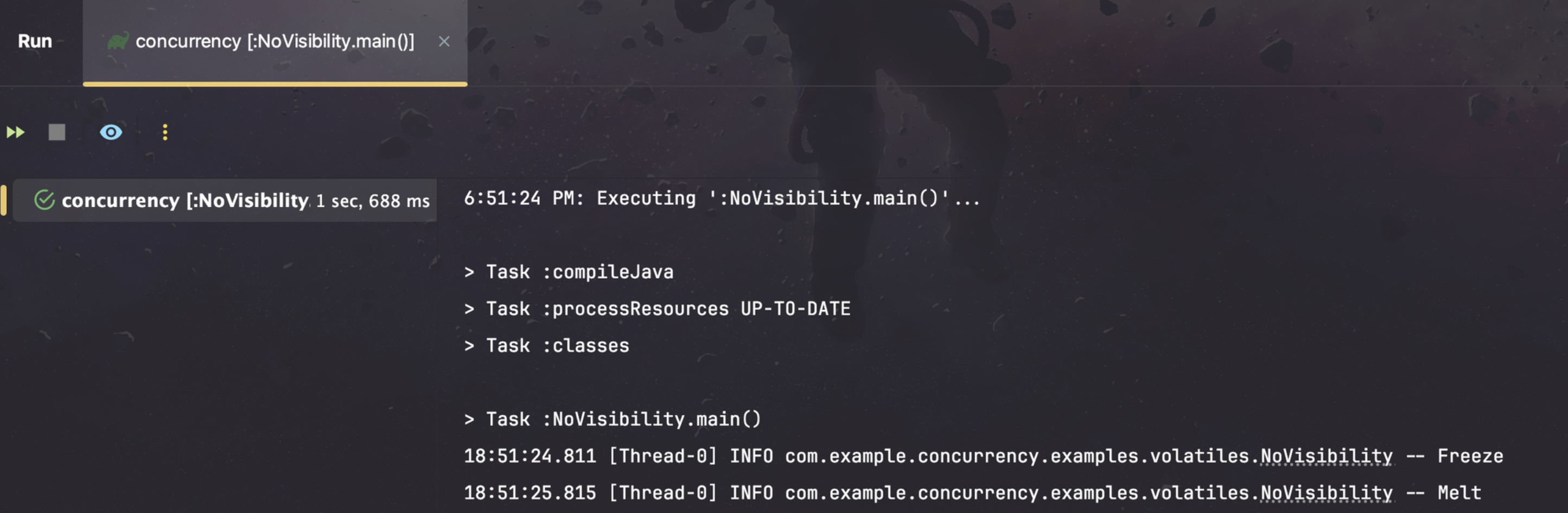
결과적으로 volatile 키워드로 인해 Main Memory에서 공유자원에 대한 수정된 값을 참조하여 1초뒤에 반복문이 종료되었습니다.
여기서 중요한점은 volatile 키워드는 가시성 문제만 해결해준다는 것인데요. 하나의 스레드에서만 값을 쓰게될 경우에는 경쟁상태가 발생하지 않을 수 있지만, 여러 스레드에서 값을 쓰게될 경우에 원자성 문제가 발생하여 경쟁상태가 발생하게됩니다.
가시성과 원자성 문제를 모두 해결하기위해서는 추가적인 해결책이 필요합니다.
이에 대한 해결책으로 Java에서 가장 대표적인 synchronized 와 Atomic Type에 대해 알아보겠습니다.
Synchronized
Java의 synchronized 키워드는 블로킹 방식의 동기화를 제공합니다. 블로킹(Blocking) 방식의 동기화는 특정 스레드가 작업을 수행하는 동안 다른 스레드는 작업을 수행하지 않고 대기하는 방식을 말합니다.
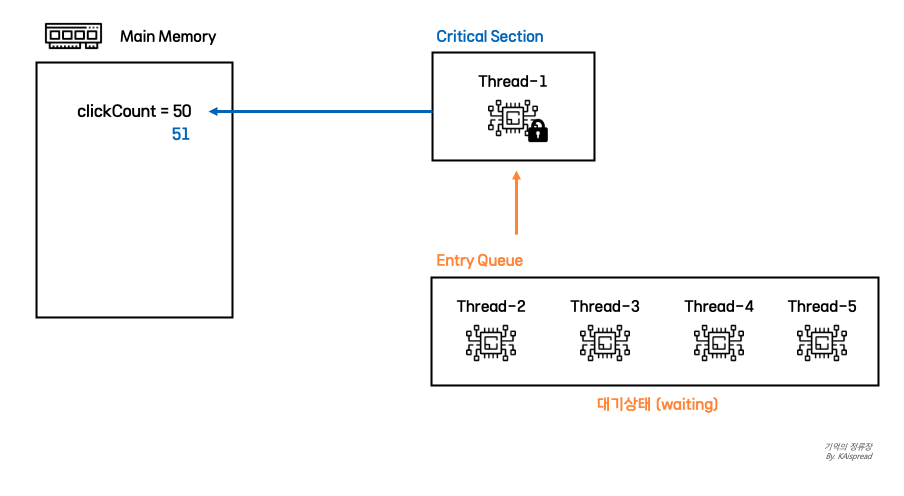
synchronzied 키워드는 동기화 기법 중 하나인 모니터를 사용하여 블로킹 동기화를 제공합니다. 모니터는 내부적으로 Mutex와 Condition Variable을 가지고 있는데요, Mutex의 Lock을 소유한 스레드만 임계 영역에 진입하여 작업을 수행할 수 있고 나머지 스레드들은 Entry Queue에 저장되어 Lock을 획득할때까지 기다리게됩니다.
이 때 Lock을 획득한 스레드가 특정 조건이 충족되어야 작업을 수행할 수 있는 상황이라면 Condition Variable의 waiting queue에 진입하고 Lock을 반환한 뒤 조건이 충족될때까지 대기합니다.
Lock을 소유한 스레드가 작업을 모두 마치고 Entry queue에 대기중인 스레드를 깨운뒤 Lock을 반환하면 깨어난 스레드가 Lock을 소유한채로 임계 영역에 진입하여 작업을 수행하게됩니다. 이와 같은 매커니즘을 통해 각 스레드들은 순차적으로 임계 영역에 진입하게되고 결과적으로 가시성과 원자성을 보장할 수 있게됩니다.
앞선 원자성 문제의 예시 코드에 synchronized 키워드를 사용해보겠습니다.
// #1
public class ClickCountService {
...
// 클릭 횟수 + 1
public synchronized void click() {
clickCount += 1;
}
}
// #2
public class ClickCountService {
...
// 클릭 횟수 + 1
public void click() {
synchronized (this) {
clickCount += 1;
}
}
}원자성 문제가 발생했던 click() 메서드에 synchronized 키워드를 사용했습니다. synchronized 키워드는 위처럼 메서드 단위에 붙일 수도 있고 synchronized block을 만들어서 사용할 수도 있습니다. 핵심은 synchronized 키워드가 붙은 블럭에 임계 영역을 만든다는 점입니다.
synchronized 키워드를 사용했으니 기대했던 값이 나오는지 테스트 결과를 확인해보겠습니다.
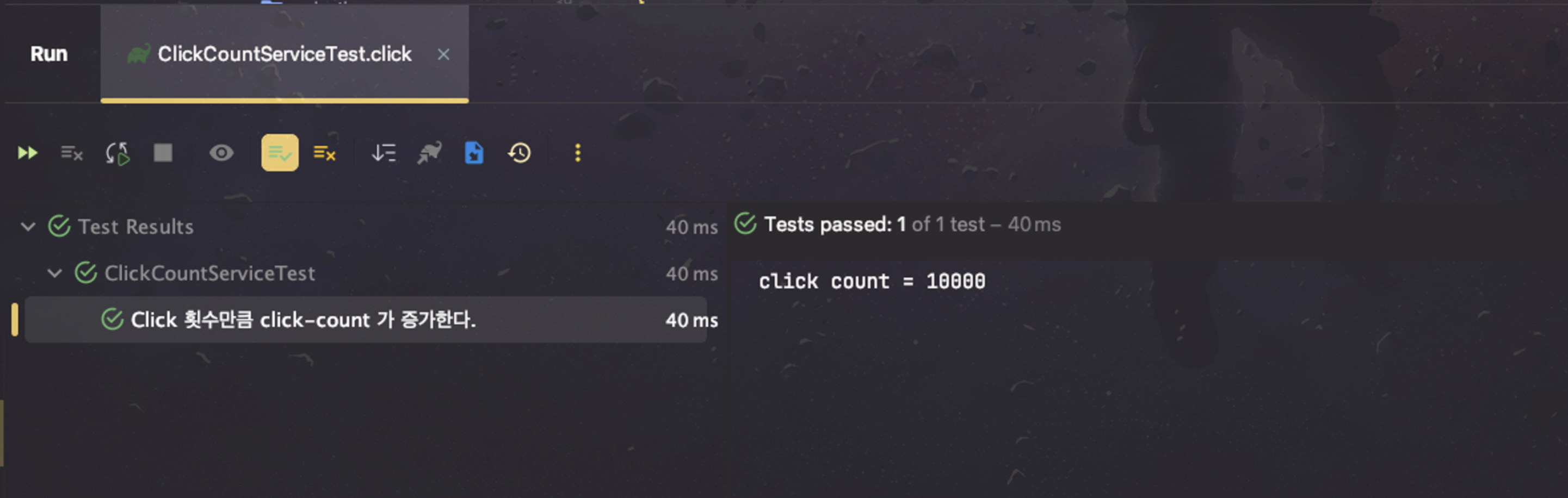
다음과 같이 기대했던 값이 나오는 것을 확인할 수 있었습니다.
하지만 이와 같은 블로킹 방식의 동기화는 몇가지 문제점이 있습니다. Lock을 소유한 스레드가 아닌 나머지 스레드들은 작업을 수행하지 못하고 대기하기 때문에 성능 이슈가 발생할 수 있다는 점과, Lock을 통해 상호 배제를 구현하기때문에 데드락 문제가 발생할 수 있다는 점입니다.
Atomic Type
Atomic Type은 동시성을 보장하기 위해 Java 에서 제공하는 Wrapper Class입니다. Atomic의 구현체로는 AtomicInteger, AtomicLong, AtomicBoolean, AtomicReference 등이 있습니다. 이전 sychronized 키워드와는 달리 논블로킹 방식의 동기화를 제공하는데요, 이와 같이 동작할 수 있는데에는 내부적으로 작업의 원자성을 위해 CAS 알고리즘을 사용하기 때문입니다.
CAS는 Compare And Set의 약자로, 값을 메인 메모리에 반영하기 전에 스레드가 기대하고 있는 기댓값과 실제 메인 메모리에 저장된 자원값을 비교하여 둘의 값이 같다면 새로운 값을 반영하는 방식입니다. 기댓값과 자원값이 다르면 값을 반영하지 않는데요, 값이 반영되지 않은 이후 어떤 동작을 수행할지는 요구사항에 따라 다르게 구현할 수 있습니다. 일반적으로는 무한 루프를 돌며 새로운 값을 반영할 수 있을때까지 반복하는 방식을 선택합니다.
Atomic의 대표 구현체인 AtomicInteger의 코드를 보며 어떻게 가시성과 원자성을 보장하는지 확인해보겠습니다.
가시성
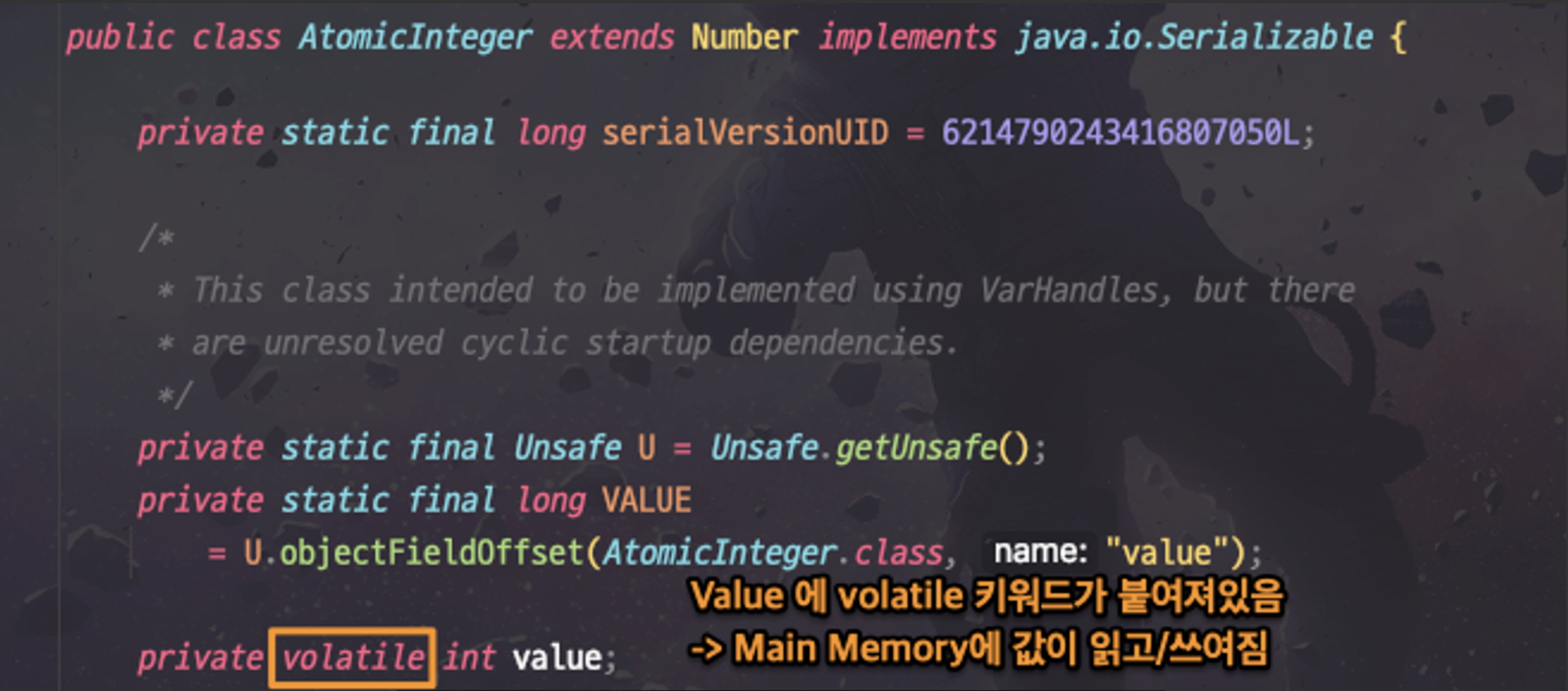
AtomicInteger는 멀티 스레드 환경에서 동시성을 보장하는, Thread-safe한 클래스인데요. 내부적으로 정수 값을 저장하는 value 변수에 volatile 키워드를 사용합니다. 이를 통해 메인 메모리에서만 값을 읽고 씀으로써 가시성 보장한다는 것을 알 수 있습니다.
원자성
AtomicInteger에서는 현재 값에 1을 더하기위한 incrementAndGet() 이라는 메서드가 있습니다. incrementAndGet() 메서드는 getAndAddInt()를 호출하는데요
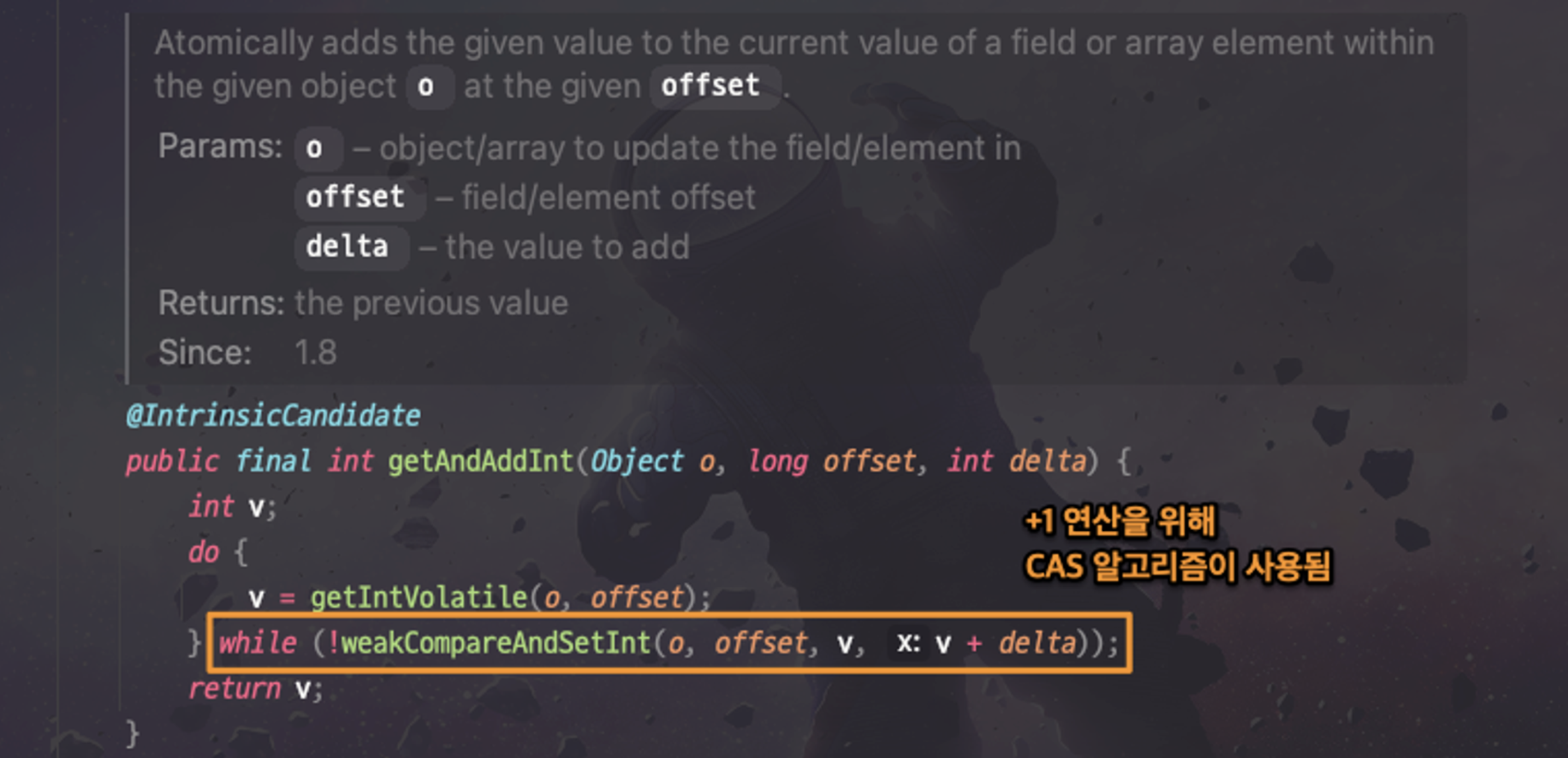
getAndAddInt 코드를 보면, +1 연산을 위해 CAS 알고리즘을 사용했다는 것을 확인할 수 있는데요. do-while 문을 통해 새로운 값을 메모리에 반영할 수 있을때까지 CAS 알고리즘을 사용한 메서드를 호출하게됩니다. 결과적으로 동시성 이슈 없이 +1 작업이 수행되는것이죠.
동시성 이슈 없이 새로운 값을 반영하고싶다면 위처럼 compareAndSet() 메서드와 do-while 문을 활용하면됩니다.
결과적으로 Atomic Type은 volatile 키워드를 통해 가시성을, CAS 알고리즘을 통해 원자성을 보장한다는 것을 확인할 수 있습니다.
마찬가지로 앞선 예시코드에 적용해보겠습니다.
// Atomic Type
public class AtomicClickCountService {
private AtomicInteger clickCount;
public AtomicClickCountService() {
this.clickCount = new AtomicInteger(0);
}
// 클릭 횟수 + 1
public void click() {
clickCount.incrementAndGet();
}
}원자성 문제가 발생했던 예제 코드에서 공유자원으로 활용되고있던 clickCount의 type을 AtomicInteger로 변경하고 clickCount를 증가시키는 작업을 incrementAndGet() 메서드로 대체하였습니다.
참고로, getAndIncrement() 도 있는데, 이는 값을 증가시키기 전의 값을 반환받을 것인지, 값을 증가시킨 이후의 값을 반환받을 것인지의 차이일 뿐 +1 연산의 작업을 수행하는 것은 동일합니다.
동일한 테스트의 결과는 다음과 같았습니다.
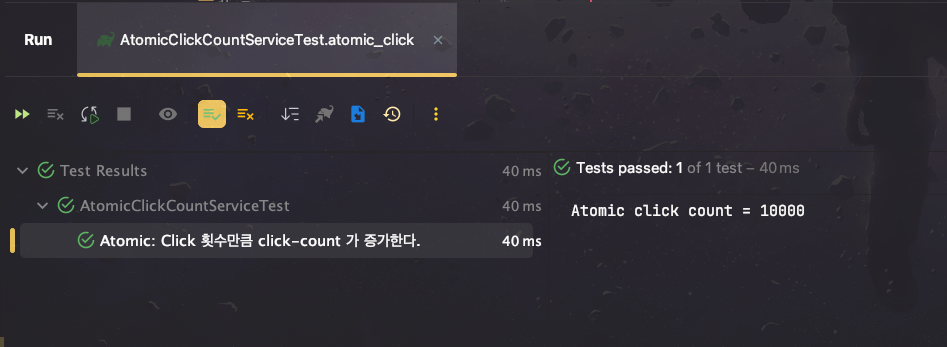
synchronized 와 마찬가지로 동시성 이슈가 발생하지 않는 것을 확인할 수 있습니다.
결론
본 포스팅에서는 멀티 스레드 환경에서 동시성 이슈가 발생하는 원인과 Java에서 해결할 수 있는 방법에 대해 알아보았습니다. 기본적인 내용이기도 하고 Thread-per-request 모델을 사용하는 백엔드 개발자로서 한번쯤 제대로 정리해야될 필요성을 느껴 이렇게 포스팅을 작성하게되었습니다.
앞서 언급한 synchronized, volatile, CAS 알고리즘은 동시성을 해결하는 여러 클래스에서 자주 사용하는 개념이기때문에 꼭 제대로 알아두시는게 좋습니다. Thread-safe한 legacy 자료구조인 HashTable과 Vector 등의 클래스는 synchronized 키워드로 동시성을 보장하고, Concurrent Collection중의 일부 클래스는 CAS 알고리즘을 사용하여 멀티 스레드 환경에서도 안전하게 동작하는데요, 이 부분에 대해서는 다음 포스팅에서 다루겠습니다.
Reference
https://www.youtube.com/watch?v=ktWcieiNzKs
https://www.youtube.com/watch?v=71dgtPrbToE&t=70s