[JPA] 연관 관계를 가진 엔티티를 저장할 때 select 문이 필요할까? (getOne() -> getReferenceById())
최근 개인 프로젝트에서 api를 만들던 중, 연관 관계를 가진 엔티티를 저장해야할 일이 생겼다.
사실, DB 테이블에는 연관 관계라는 것이 없고 해당 테이블의 FK(ID 값)만 맞춰주면 되는데 JPA가 패러다임의 차이를 극복해주기 때문에 Entity라는 객체를 필드에 저장하도록 설계되어있다.
따라서, 엔티티를 저장할 때 연관 관계를 나타내는 필드들도 객체로 채워주어야 한다.
문제 상황
다음은 ANSWER 테이블을 나타내는 Entity이다.
@Getter
@NoArgsConstructor
@Entity
public class Answer {
@Column(name = "ANSWER_ID")
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "USER_ID")
private User user;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "SURVEY_ID")
private Survey survey;
...
}이 Answer이라는 Entity를 DB에 저장할 때, 연관 관계에 있는 user과 survey 필드도 당연히 채워주어야 한다. FK가 null인 경우도 있지만 무결성 조건에 위배되고 이미 USER_ID 값과 SURVEY_ID 값을 알고있어서 그렇게 할 필요도 없다.
문제 제기
@Override
public Long save(SurveyAnswerRequestDto surveyAnswerRequestDto, Long surveyId, Long userId) {
User user = userRepository.findById(userId).orElseThrow(
() -> new IllegalArgumentException("해당 유저가 없습니다.")
);
Survey survey = surveyRepository.findById(surveyId).orElseThrow(
() -> new IllegalArgumentException("해당 설문이 없습니다.")
);
return answerRepository.save(surveyAnswerRequestDto.toEntity(survey, user)).getId();
}
처음 구현할 때는 엔티티를 저장하기 위해, findById() 메서드로 직접 DB에서 연관된 엔티티를 조회하였다.
그런데 보면 볼수록 뭔가 찝찝하다.. findById() 메서드로 엔티티를 불러오면 실제 DB에 insert문 뿐만 아니라 select 쿼리가 추가로 발생할텐데 당연히 성능에도 문제가 생길 것이고 N+1 문제를 내가 직접 만들고 있는듯한 느낌이 들었다.
무엇보다 이 메서드의 역할은 단지 엔티티를 DB에 '저장'만하는 것이였다.
그렇다고 Id값만을 이용해 새로운 User, Survey 객체를 생성하자니, 아무 의미없는 Entity를 맘대로 생성하면 안될것같다는 생각이 들었다. Dto가 괜히 있는게 아니다.
해결 방안 - getOne()
해당 코드를 개선하기 위해 관련 정보를 찾아본 결과, 다음과 같은 메서드가 있었다.
@Override
public Long save(SurveyAnswerRequestDto surveyAnswerRequestDto, Long surveyId, Long userId) {
User user = userRepository.getOne(userId);
Survey survey = surveyRepository.getOne(surveyId);
return answerRepository.save(surveyAnswerRequestDto.toEntity(survey, user)).getId();
}Spring Data JPA에서 getOne() 이라는 메서드는 엔티티를 직접 조회하는 것이 아닌, 엔티티의 참조를 반환한다. 다시 말해, getOne() 메서드는 엔티티를 상속받은 프록시 객체가 반환되어 실제 해당 객체가 값에 접근할 때 쿼리가 발생하게 된다. 가짜 프록시 객체를 가져오는 것이기 때문에 불필요한 select 쿼리가 발생하지 않는다.
JPA의 지연 로딩도 이러한 방식을 사용한다. 프록시 객체는 실제 객체의 참조(target)를 보관한다. 이후, 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메서드를 호출한다.
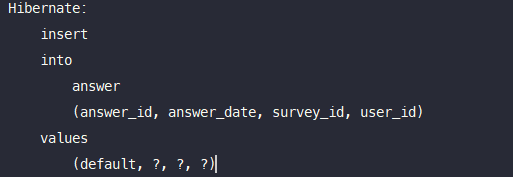
실제로 insert문 하나만 발생한다.
getOne() 대신 getReferenceById()를 사용하자.
Spring Data JPA의 API docs (2.7.3 버전 기준)를 보면 다음과 같이 나와있다.
https://docs.spring.io/spring-data/jpa/docs/current/api/

getOne() 메서드는 Deprecated 되었고 대신 getReferenceById() 를 사용하라고 안내하고 있다.
해당 메서드로 변경하자.
@Override
public Long save(SurveyAnswerRequestDto surveyAnswerRequestDto, Long surveyId, Long userId) {
User user = userRepository.getReferenceById(userId);
Survey survey = surveyRepository.getReferenceById(surveyId);
return answerRepository.save(surveyAnswerRequestDto.toEntity(survey, user)).getId();
}- getOne() → getReferenceById() 로 변경
결론
연관 관계에 있는 엔티티를 저장하기 위해 findById() 메서드를 사용하여 Entity를 불러왔고, 이는 불필요한 select문이 발생하는 결과를 낳았다.
이를 개선하기 위해 findById() 메서드 대신, getReferenceById() 메서드를 사용하여 엔티티 생성에 프록시 객체를 넣어주었다. 따라서 select 문이 제거되었다.
하지만 findById() 메서드는 Optional로 반환되기때문에 예외 처리에 유리하지만, getReferenceById() 는 프록시 객체를 가져오기 때문에 예외 발생 위험이 있다. 따라서 이 부분을 조심해야겠다는 생각이 들었다.
Reference.