
✍페치 조인(Fetch Join)
- 실무에서 매우매우매우매우 중요함.
- - 페치 조인은 SQL 조인 종류가 아님.
- JPQL에서 성능 최적화를 위해 제공
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- join fetch 명령어 사용
💠 엔티티 페치 조인
ex) 회원을 조회하면서 연관된 팀도 함께 조회하고 싶을 때 (SQL 한 번에) / 다대일 관계, 일대일 관계
SQL을 보면 회원 뿐만 아니라 팀(T.*)도 함께 SELECT
ㆍ[JPQL] - SELECT m FROM Member m join fetch m.team
ㆍ[SQL] - SELECT M.*, T.* FROM Member m INNER JOIN TEAM T ON M.TEAM_ID = T.ID
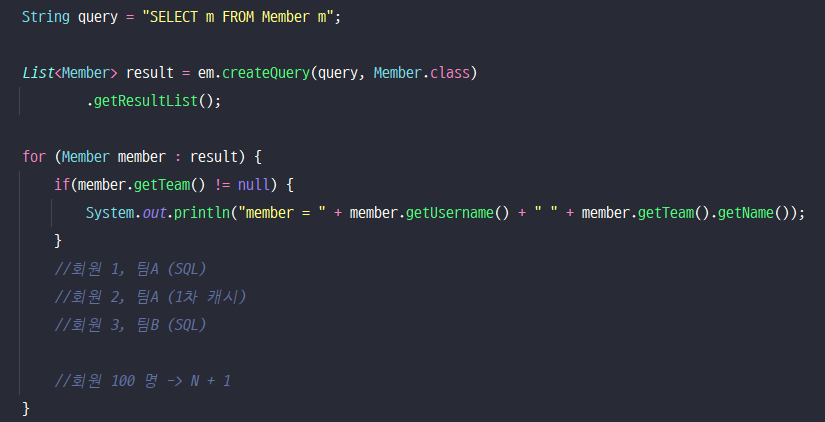
- "SELECT m FROM Member m" 쿼리는 Member의 Team에 대한 엔티티를 지연 로딩으로 설정하였기 때문에, 쿼리를 날릴 때 Team에 프록시 객체가 들어감.
- 이후, Team에 대한 정보를 가져올 때 Team에 대한 쿼리가 발생
🍁 N + 1 문제?
- Entity를 가져오고 ( 1 ) 연관된 Entity 컬렉션을 가져오기 위해서 N번 SQL 쿼리문을 날리는 현상. // N + 1
- 즉시 로딩, 지연 로딩으로 해결할 수 없다.
- Fetch Join으로 해결.
💡 Fetch Join
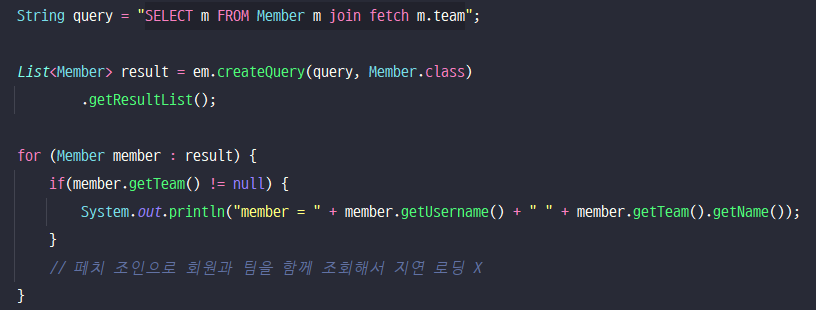
- "SELECT m FROM Member m join fetch m.team" 으로 페치 조인을 하면, 연관된 엔티티를 전부 한꺼번에 조회. 따라서, Team은 프록시 객체가 아닌, 엔티티 객체가 들어감. 따라서, 영속성 컨텍스트에 존재하게 됨.
- 즉시 로딩 전략과는 달리, 개발자가 함께 조회할 상황을 지정할 수 있고, 명시적으로 JOIN을 날릴 수 있음.
💠 컬렉션 페치 조인
일대다 관계, 컬렉션 페치 조인
ㆍ[JPQL] - SELECT t FROM Team t join fetch t.members WHERE t.name = '팀A'
ㆍ[SQL]
SELECT T.*, M.*
FROM TEAM T
INNER JOIN MEMBER M ON T.ID = M.TEAM_ID
WHERE T.NAME = '팀A'
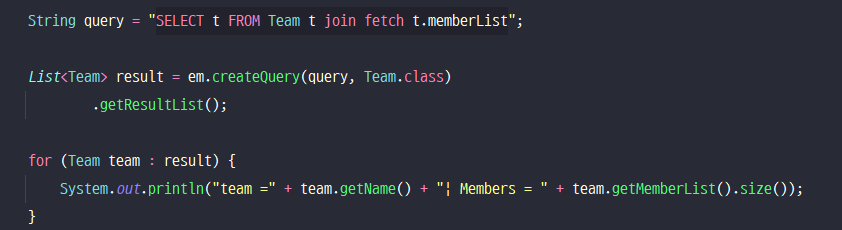
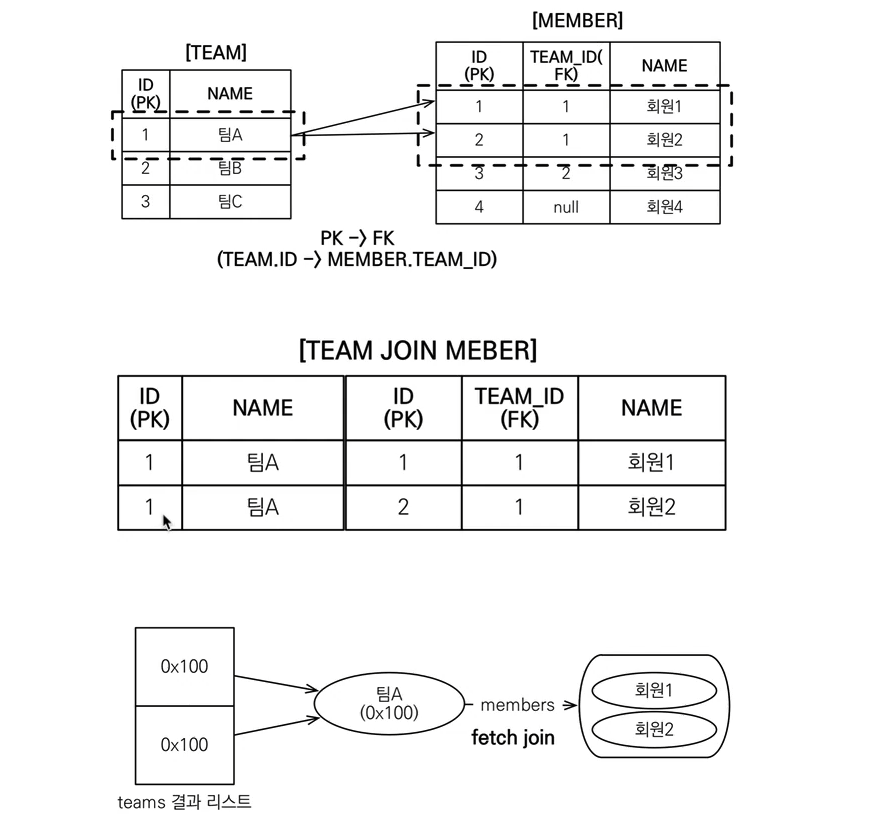
Team을 Select 하였지만, join으로 각 Team에 대한 MemberList도 가져왔기 때문에 DB에서 Team은 하나이더라도 Member의 수에 따라 데이터가 여러개 불려올 수 있다.
- DB에서는 같은 데이터라도 JOIN으로 인해 값이 여러개 발생할 수 있다. JPA 입장에서는 같은 주소 값을 가지는 데이터가 여러개 생기는 것. 패러다임 차이라 어쩔 수 없음
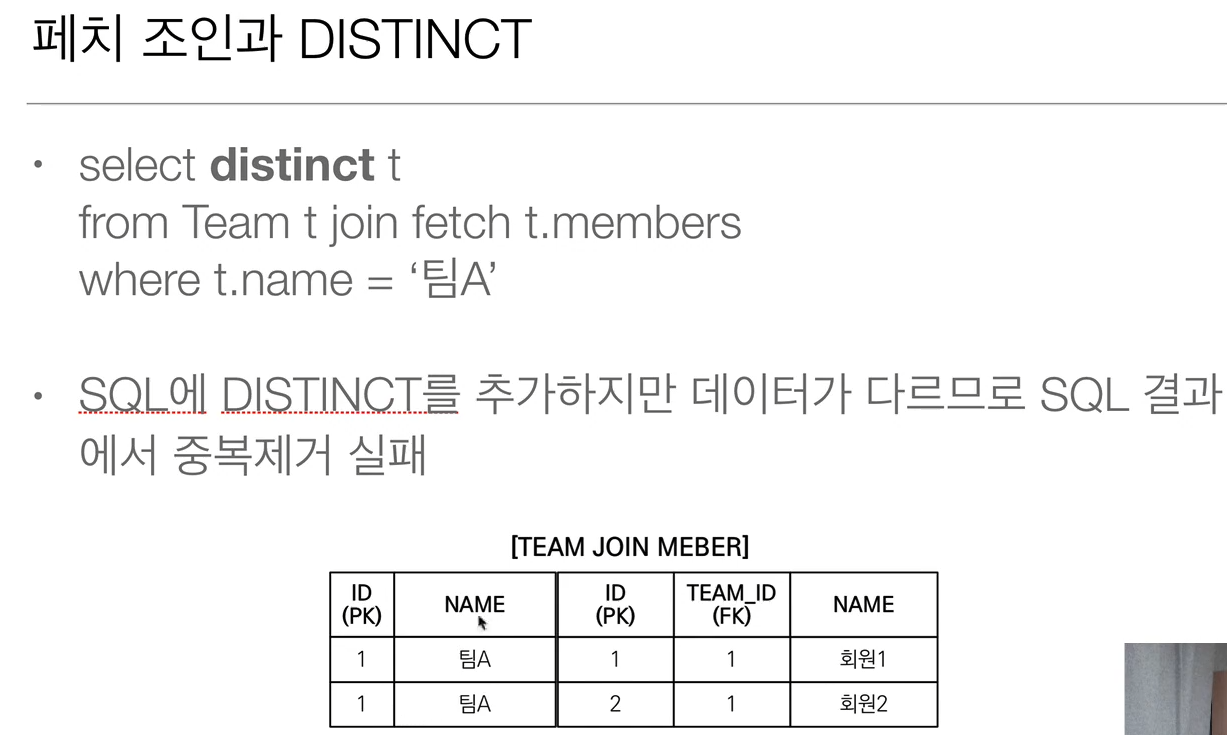
💡 페치 조인과 DISTINCT
- SQL의 DISTINCT는 중복된 결과를 제거하는 명령이다.
- JPQL의 DISTINCT 2가지 기능을 제공.
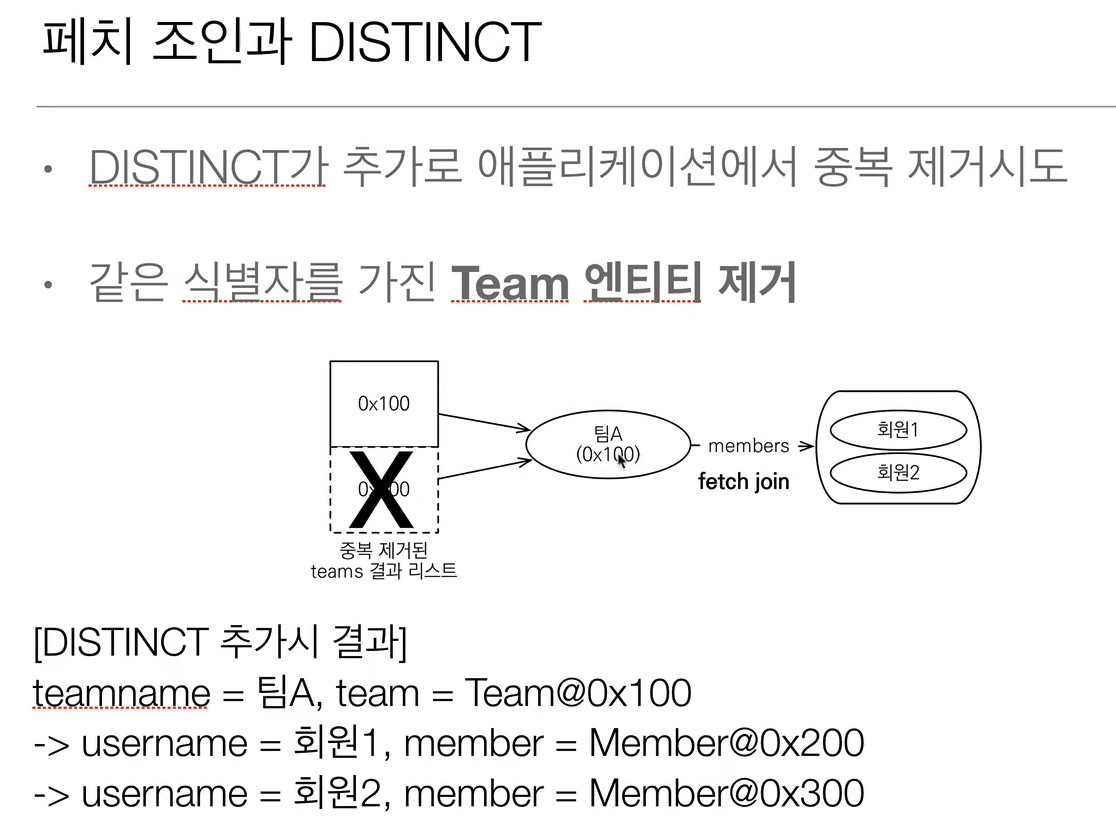
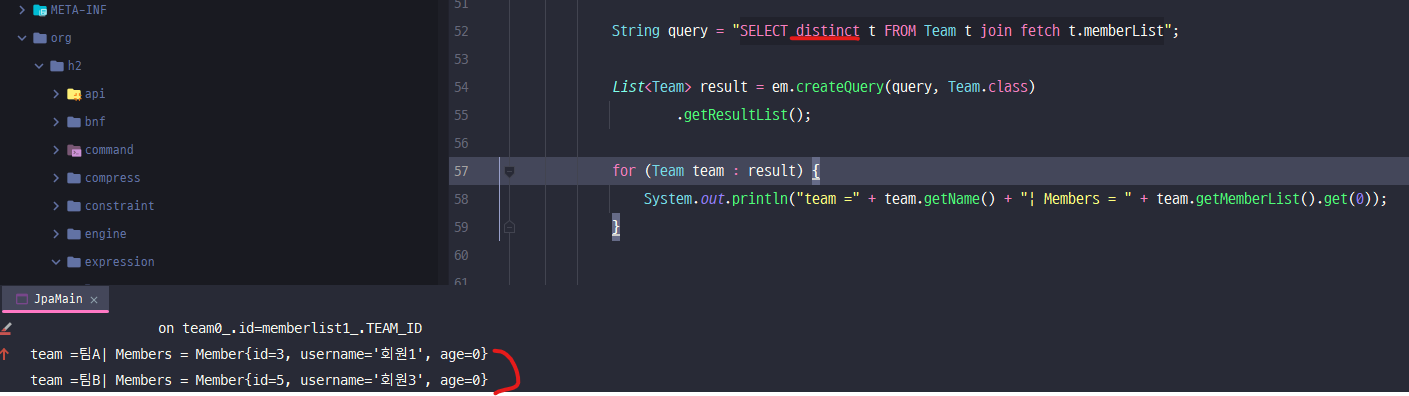
-> 1. SQL에 DISTINCT를 추가 / 객체 입장에서는 그닥 효용이 없다.
-> 2. 애플리케이션에서 엔티티 중복 제거.
💡 페치 조인과 일반 조인의 차이
- 일반 조인 실행시에는 연관된 엔티티를 함께 조회하지 않음. 단지, SELECT 절에 지정한 엔티티만 조회.
- 따라서 연관된 엔티티에 접근하고자 할 때, SQL 쿼리가 나감.
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회 (즉시 로딩 동작)
- 페치 조인은 객체 그래프를 SQL 한번에 조회하는 개념이다.
💠 페치 조인의 특징과 한계
1. 페치 조인 대상에는 별칭을 줄 수 없다. (하이버네이트는 가능하지만 가급적 사용 X) - 정확성 이슈 발생 가능성 [위험]
=> 페치 조인은 기본적으로 연관된 데이터를 전부 가져오도록 설계되어있음.
=> 따라서, 페치 조인 대상에 조건을 주고 특정한 데이터만 가져오고 싶다면, 따로 해당 엔티티를 가져오는 SQL을 날리는게 맞다.
2. 둘 이상의 컬렉션은 페치 조인 할 수 없다.
=> 데이터 뻥튀기가 제곱으로 늘어나기때문에 사용 X
3. 컬렉션을 페치 조인하면 페이징 API를 사용할 수 없다.
ㆍ 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
ㆍ 일대다, 다대다 같은 컬렉션 값을 저장하는 필드는 데이터 뻥튀기가 일어나기 때문에 데이터가 특정 개수만큼 필터링 될 수 없음.
ㆍ 하이버네이트는 경고 로그를 남기고 메모리에서 페이징함. (매우 위험)

=> 컬렉션을 페치 조인 시 페이징 API를 사용할 수 없기 때문에 해당 엔티티 컬렉션 필드에 BatchSize를 지정한다. 일반적으로 큰 수를 지정. 이후, 페치 조인을 하지 않고 엔티티를 그냥 가져와서 연관된 엔티티를 사용한다.
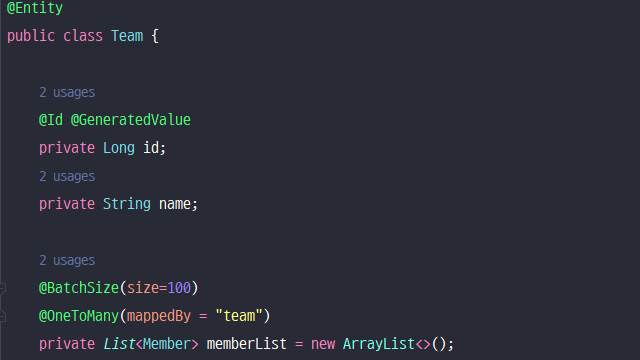
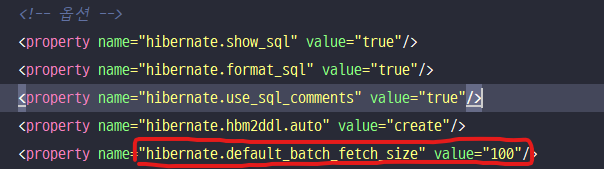
persistence.xml 에서 글로벌 세팅으로 지정할 수도 있다.

- JPA의 성능문제 7~80% 전부 Fetch Join으로 잡을 수 있음.

본 게시글은 김영한님의 Inflearn 강의를 토대로 제작되었습니다.
https://www.inflearn.com/course/ORM-JPA-Basic/dashboard
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., - 강의 소개 | 인프런
www.inflearn.com
✍페치 조인(Fetch Join)
- 실무에서 매우매우매우매우 중요함.
- - 페치 조인은 SQL 조인 종류가 아님.
- JPQL에서 성능 최적화를 위해 제공
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- join fetch 명령어 사용
💠 엔티티 페치 조인
ex) 회원을 조회하면서 연관된 팀도 함께 조회하고 싶을 때 (SQL 한 번에) / 다대일 관계, 일대일 관계
SQL을 보면 회원 뿐만 아니라 팀(T.*)도 함께 SELECT
ㆍ[JPQL] - SELECT m FROM Member m join fetch m.team
ㆍ[SQL] - SELECT M.*, T.* FROM Member m INNER JOIN TEAM T ON M.TEAM_ID = T.ID
- "SELECT m FROM Member m" 쿼리는 Member의 Team에 대한 엔티티를 지연 로딩으로 설정하였기 때문에, 쿼리를 날릴 때 Team에 프록시 객체가 들어감.
- 이후, Team에 대한 정보를 가져올 때 Team에 대한 쿼리가 발생
🍁 N + 1 문제?
- Entity를 가져오고 ( 1 ) 연관된 Entity 컬렉션을 가져오기 위해서 N번 SQL 쿼리문을 날리는 현상. // N + 1
- 즉시 로딩, 지연 로딩으로 해결할 수 없다.
- Fetch Join으로 해결.
💡 Fetch Join
- "SELECT m FROM Member m join fetch m.team" 으로 페치 조인을 하면, 연관된 엔티티를 전부 한꺼번에 조회. 따라서, Team은 프록시 객체가 아닌, 엔티티 객체가 들어감. 따라서, 영속성 컨텍스트에 존재하게 됨.
- 즉시 로딩 전략과는 달리, 개발자가 함께 조회할 상황을 지정할 수 있고, 명시적으로 JOIN을 날릴 수 있음.
💠 컬렉션 페치 조인
일대다 관계, 컬렉션 페치 조인
ㆍ[JPQL] - SELECT t FROM Team t join fetch t.members WHERE t.name = '팀A'
ㆍ[SQL]
SELECT T.*, M.*
FROM TEAM T
INNER JOIN MEMBER M ON T.ID = M.TEAM_ID
WHERE T.NAME = '팀A'
Team을 Select 하였지만, join으로 각 Team에 대한 MemberList도 가져왔기 때문에 DB에서 Team은 하나이더라도 Member의 수에 따라 데이터가 여러개 불려올 수 있다.
- DB에서는 같은 데이터라도 JOIN으로 인해 값이 여러개 발생할 수 있다. JPA 입장에서는 같은 주소 값을 가지는 데이터가 여러개 생기는 것. 패러다임 차이라 어쩔 수 없음
💡 페치 조인과 DISTINCT
- SQL의 DISTINCT는 중복된 결과를 제거하는 명령이다.
- JPQL의 DISTINCT 2가지 기능을 제공.
-> 1. SQL에 DISTINCT를 추가 / 객체 입장에서는 그닥 효용이 없다.
-> 2. 애플리케이션에서 엔티티 중복 제거.
💡 페치 조인과 일반 조인의 차이
- 일반 조인 실행시에는 연관된 엔티티를 함께 조회하지 않음. 단지, SELECT 절에 지정한 엔티티만 조회.
- 따라서 연관된 엔티티에 접근하고자 할 때, SQL 쿼리가 나감.
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회 (즉시 로딩 동작)
- 페치 조인은 객체 그래프를 SQL 한번에 조회하는 개념이다.
💠 페치 조인의 특징과 한계
1. 페치 조인 대상에는 별칭을 줄 수 없다. (하이버네이트는 가능하지만 가급적 사용 X) - 정확성 이슈 발생 가능성 [위험]
=> 페치 조인은 기본적으로 연관된 데이터를 전부 가져오도록 설계되어있음.
=> 따라서, 페치 조인 대상에 조건을 주고 특정한 데이터만 가져오고 싶다면, 따로 해당 엔티티를 가져오는 SQL을 날리는게 맞다.
2. 둘 이상의 컬렉션은 페치 조인 할 수 없다.
=> 데이터 뻥튀기가 제곱으로 늘어나기때문에 사용 X
3. 컬렉션을 페치 조인하면 페이징 API를 사용할 수 없다.
ㆍ 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
ㆍ 일대다, 다대다 같은 컬렉션 값을 저장하는 필드는 데이터 뻥튀기가 일어나기 때문에 데이터가 특정 개수만큼 필터링 될 수 없음.
ㆍ 하이버네이트는 경고 로그를 남기고 메모리에서 페이징함. (매우 위험)
=> 컬렉션을 페치 조인 시 페이징 API를 사용할 수 없기 때문에 해당 엔티티 컬렉션 필드에 BatchSize를 지정한다. 일반적으로 큰 수를 지정. 이후, 페치 조인을 하지 않고 엔티티를 그냥 가져와서 연관된 엔티티를 사용한다.
persistence.xml 에서 글로벌 세팅으로 지정할 수도 있다.
- JPA의 성능문제 7~80% 전부 Fetch Join으로 잡을 수 있음.
본 게시글은 김영한님의 Inflearn 강의를 토대로 제작되었습니다.
https://www.inflearn.com/course/ORM-JPA-Basic/dashboard
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., - 강의 소개 | 인프런
www.inflearn.com