
728x90
반응형
- SELECT 문의 기본 형식은 다음과 같다.
SELECT 열_이름
FROM 테이블_이름
WHERE 조건식
GROUP BY 열_이름
HAVING 조건식
ORDER BY 열_이름
LIMIT 숫자
📌 USE - 스키마 (데이터베이스) 선택
-- USE '스키마명'
USE market_db;- USE 문을 사용하여 SQL을 사용할 스키마를 지정할 수 있다.
📌 SELECT - 조회할 데이터(컬럼) 지정
-- SELECT '컬럼명' FROM '테이블명'
SELECT member_id, name FROM member;
-- SELECT 와 FROM 사이에 *를 적으면 테이블의 모든 컬럼을 조회한다.
SELECT * FROM member;
-- 두 SQL은 동일한 기능을 한다.
SELECT * FROM market_db.member;
SELECT * FROM member;- 기본적으로 테이블 이름은 스키마명.테이블명 으로 표현한다.
- 하지만 USE 문으로 데이터베이스를 지정해주었다면 테이블명만 명시해도 된다.
📌 WHERE - 특정 조건만 조회하기
-- member 테이블에서 mem_number 컬럼 값이 5이상인 데이터 조회
SELECT * FROM member
WHERE mem_number >= 5;- WHERE절을 사용해 특정 조건에 해당하는 데이터만 조회할 수 있다.
- 관계 연산자 / 논리 연산자 사용 가능
논리 연산자 AND, OR 사용 가능
SELECT TRUE OR FALSE AND FALSE; // 1
SELECT (TRUE OR FALSE) AND FALSE; // 0- 여러 조건이 필요한 경우 논리 연산자를 사용하면 된다.
- AND가 OR보다 우선 순위를 가진다.
- MySQL에서는 && 나 || 도 사용 가능하다.
BETWEEN - 범위 표현식
-- member 테이블에서 height 컬럼 값이 160이상 165이하인 데이터 조회
SELECT * FROM member
WHERE height between 160 and 165;- between 연산자를 이용하여 특정 범위에 해당하는 데이터를 조회할 수 있다.
- 하지만 인덱스를 사용할 수 없으므로 주의
IN () - 여러 값 매칭
-- addr 컬럼값이 경기, 전남, 경남인 데이터 조회
SELECT * FROM member
WHERE addr IN('경기', '전남', '경남');
SELECT * FROM member
WHERE addr = '경기' OR addr = '전남' OR addr = '경남';- IN() 연산자를 이용하여 특정 값이 포함된 데이터를 조회할 수 있다.
- IN 연산자는 동등비교 '=' 를 여러번 수행하는 효과를 가진다. 따라서 인덱스를 최적으로 활용할 수 있다.
LIKE - 문자열의 일부 글자 검색
-- mem_name 컬럼 값이 '블'로 시작하는 4글자 글자 데이터 조회
SELECT * FROM member WHERE mem_name LIKE '블___';
-- mem_name 컬럼 값이 '블'로 시작하는 모든 데이터 조회
SELECT * FROM member WHERE mem_name LIKE '블%';
-- mem_name 컬럼 값에 '블'이 들어가는 모든 데이터 조회
SELECT * FROM member WHERE mem_name LIKE '%블%';- 문자열의 일부 글자 검색
- _ : 한 글자만 매치
- % : 몇 글자든 매치
서브 쿼리
SELECT mem_name, height
FROM member
WHERE height > (select height from member where mem_name LIKE '에이핑크');- 2개의 SQL 문을 하나로 만듦
📌 ORDER BY - 조회된 데이터를 정렬
-- debut_date 값을 기준으로 정렬 (기본 ASC)
SELECT * FROM member
ORDER BY debut_date;- ORDER BY 절은 데이터를 정렬한다.
- WHERE 절 다음에 나와야 함
- ASC (ascending order) : 오름차순 → (생략시 기본값)
- DESC (descending order) : 내림차순
-- height 컬럼 값이 164 이상인 데이터를 조회하여
-- height 값 기준 내림차순 정렬하고 동일한 값이라면 debut_date 값 기준 오름차순 정렬
SELECT * FROM member
WHERE height >= 164
ORDER BY height DESC, debut_date;- 콤마 , 로 여러 정렬 조건 지정 가능
📌 LIMIT - 출력 개수 제한
SELECT * FROM member
LIMIT 3; -- 상위 3건만 조회
SELECT * FROM member
LIMIT 3, 2; -- 3번째 데이터부터 2건만 조회
LIMIT 2 OFFSET 3; -- 위와 동일- LIMIT 시작, 개수
- LIMIT 뒤에 하나의 숫자만 입력시 처음부터 N까지의 데이터만 가져옴
- LIMIT 과 OFFSET 조합으로도 출력 개수를 제한할 수 있다.
📌 DISTINCT - 중복 데이터 제거
-- addr 의 모든 컬럼 값을 중복을 제거하여 조회
SELECT DISTINCT addr
FROM member;- DISTINCT를 열 이름 앞에 붙이면 중복된 값은 1개만 출력된다.
📌 GROUP BY - 그룹화
-- mem_id가 같은 데이터를 그룹으로 묶음
-- 그룹핑된 데이터에서 mem_id와 amount의 합계를 구함
SELECT mem_id, SUM(amount) AS "합계"
FROM buy
GROUP BY mem_id
ORDER BY mem_id;- 컬럼이 같은 데이터를 그룹화 해주는 기능
- 보통 집계 함수와 같이 쓰임
SELECT genre, AVG(price) AS "평균"
FROM library
GROUP BY genre;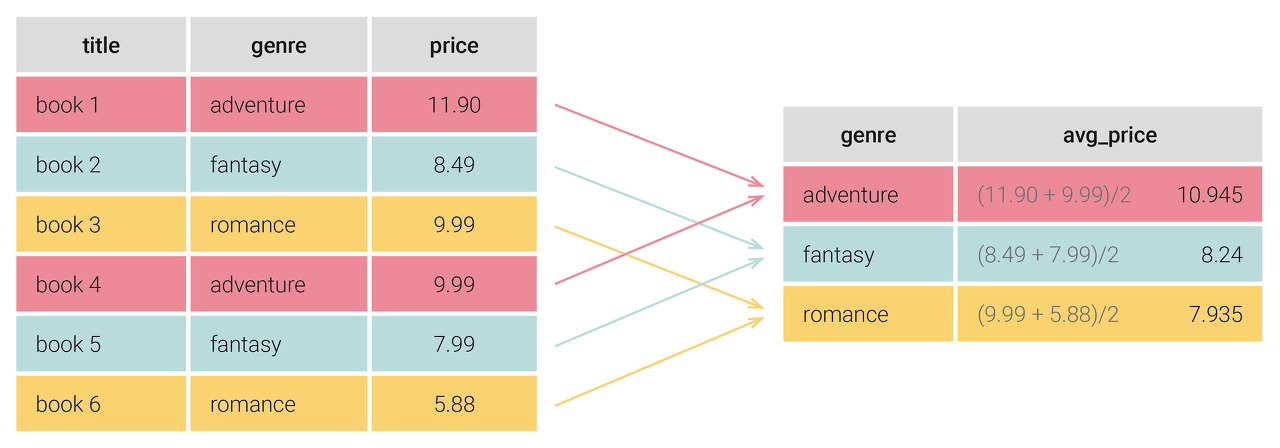
- GROUP BY 로 지정한 컬럼이 같은 데이터끼리 그룹화
- 여러 컬럼 지정 가능
집계 함수 (Aggregate Function)
- SUM() : 컬럼의 합계를 반환
- AVG() : 컬럼의 평균을 반환
- MIN() : 컬럼의 최소값을 반환
- MAX() : 컬럼의 최대값을 반환
- COUNT() : 행의 개수를 셈
- COUNT(DISTINCT) : 행의 개수를 셈
-- 집계 함수 안에서 연산도 가능
SELECT mem_id, SUM(amount*price) AS "총 금액"
FROM buy
GROUP BY mem_id
ORDER BY mem_id;- 집계 함수 내에서 사칙 연산도 가능하다.
COUNT()
-- member 테이블의 모든 데이터 개수를 셈
SELECT COUNT(*)
FROM member;
-- member 테이블의 phone1 컬럼이 NULL인 것을 제외한 모든 데이터 개수를 셈
SELECT COUNT(phone1)
FROM member;- COUNT(*) 연산은 모든 row를 대상으로 이루어지기 때문에 NULL값이 포함되어있어도 카운트됨
- COUNT(phone1) 연산은 phone1 값에 NULL이 있을 경우 카운트하지 않음
📌 HAVING - 그룹 조건
-- mem_id 를 기준으로 그룹화
-- 그룹화된 데이터를 기준으로 amount*price 합계가 1000 이상인 그룹만 남김
-- 조건에 걸러진 그룹에서 amount*price 의 합계를 조회
SELECT SUM(amount*price) AS "총 금액"
FROM buy
GROUP BY mem_id
HAVING SUM(amount*price) >= 1000;- 그룹화된 데이터에 대해서 조건을 제한함
- GROUP BY 뒤에 와야함
728x90
반응형